In Progress (Targeting ICML 2026)
New Benchmark Reveals Coordination as Fundamental Challenge for Multi-Agent AI Systems
Khatua, A.¹, Zhu, H.¹, Tran, P.², Prabhudesai, A.², Yu, X.¹, Sadrieh, F.², Lieberwirth, J. K.², Fu, Y.¹, Ryan, M. J.¹, Pei, J.¹, & Yang, D.¹ (¹Stanford University, ²SAP)
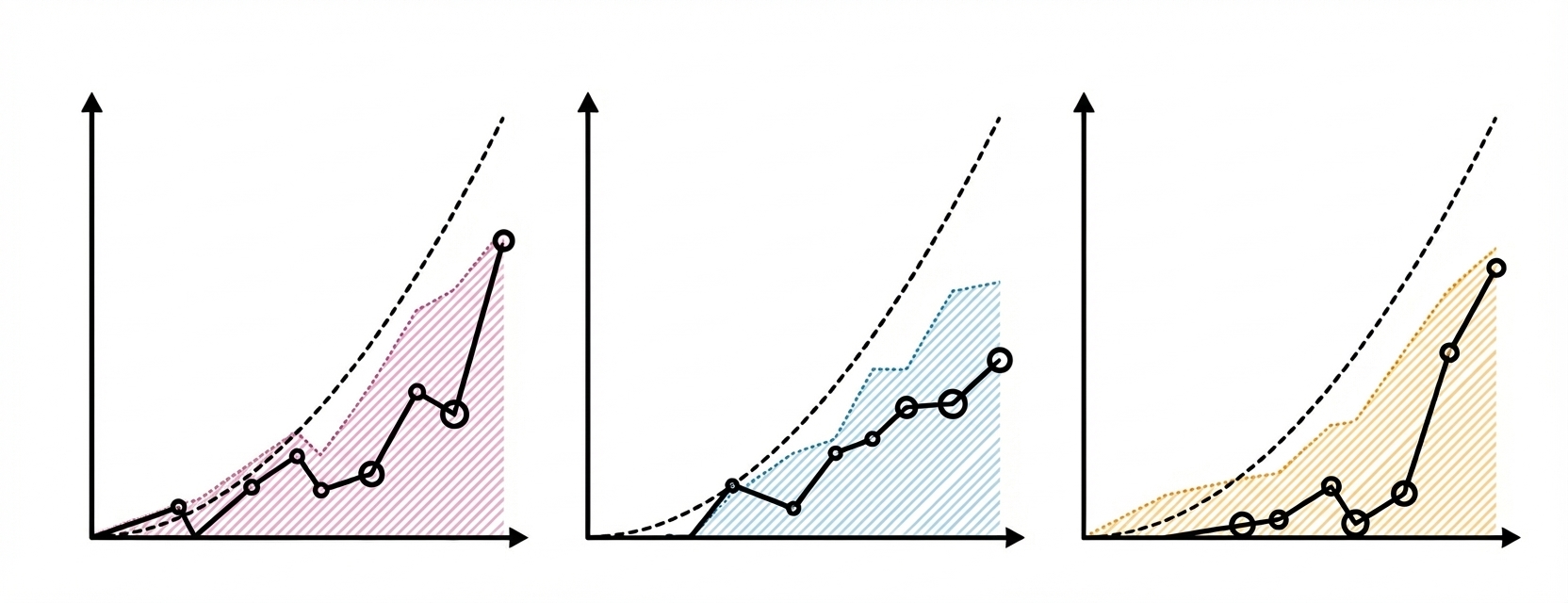
Initial results from Cotomata, a multi-agent collaboration benchmark, show that LLM coordination in version-controlled programming environments suffers dramatically. Models drop from 70-75% accuracy (single-agent) to 20-30% (multi-agent), with majority of failures attributed to mismatched shared-state assumptions. The benchmark includes multi-agent interaction protocols and a failure analysis pipeline.